Method
Unified Video-Action Policy
Adapts a pretrained video diffusion transformer into an end-to-end driving policy via joint flow-matching over video and action tokens.
Scene-Evolving Guidance
A frozen VLM generates chunk-specific semantic intent injected via temporally localized cross-attention, enabling scene-level reasoning.
Selective KV Memory
Training-free modality-aware cache selection retains salient tokens and discards redundancy — 12× memory reduction for 300s rollouts.
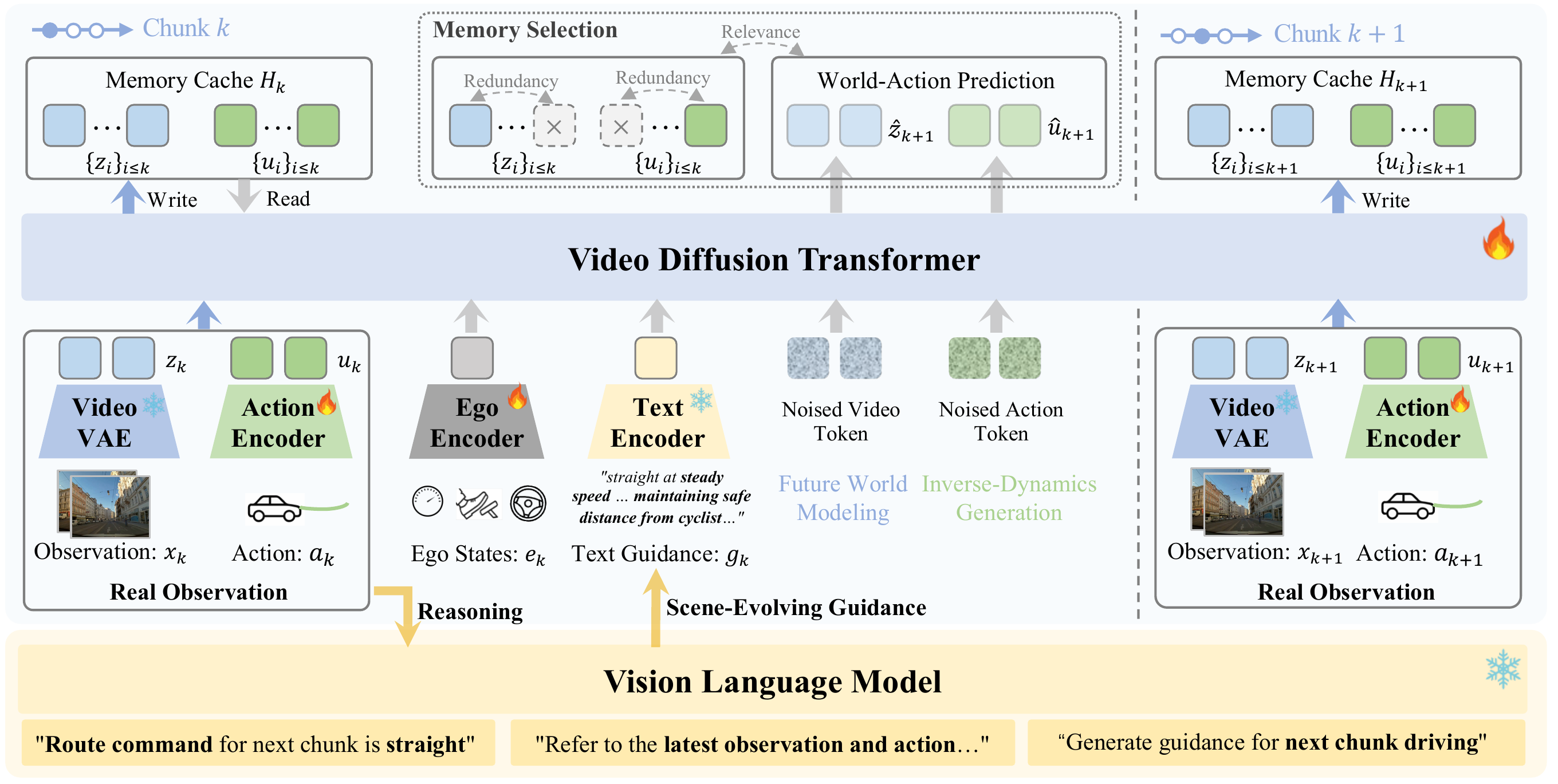
Overview of DriveWAM. Video and action tokens are organized into a unified temporal sequence within a pretrained video diffusion transformer. A frozen VLM provides scene-evolving driving guidance via chunk-specific cross-attention, and selective KV memory maintains bounded context for long-horizon autoregressive rollout.
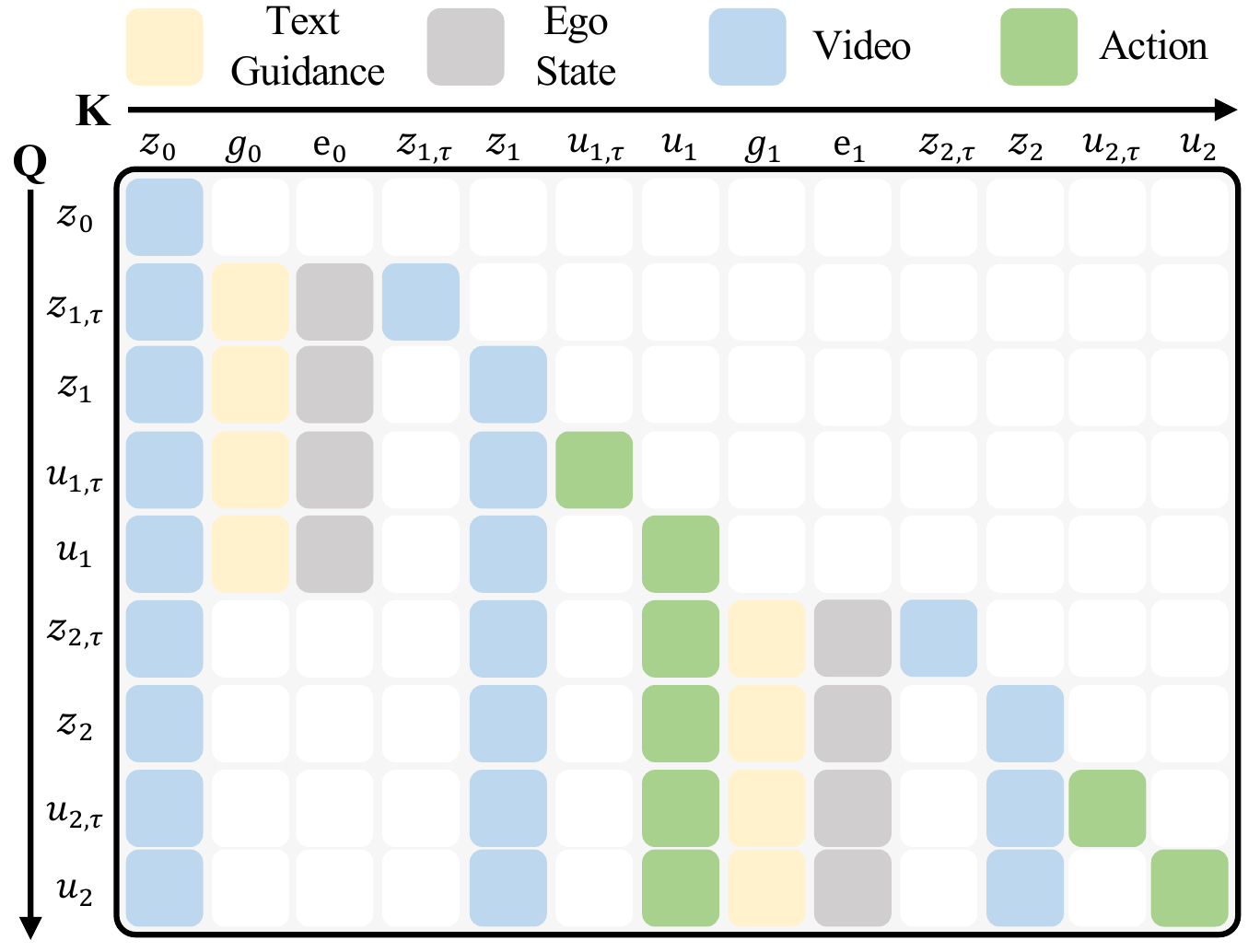
Training attention mask. Block-diagonal design ensures causal dependencies while preventing future information leakage.

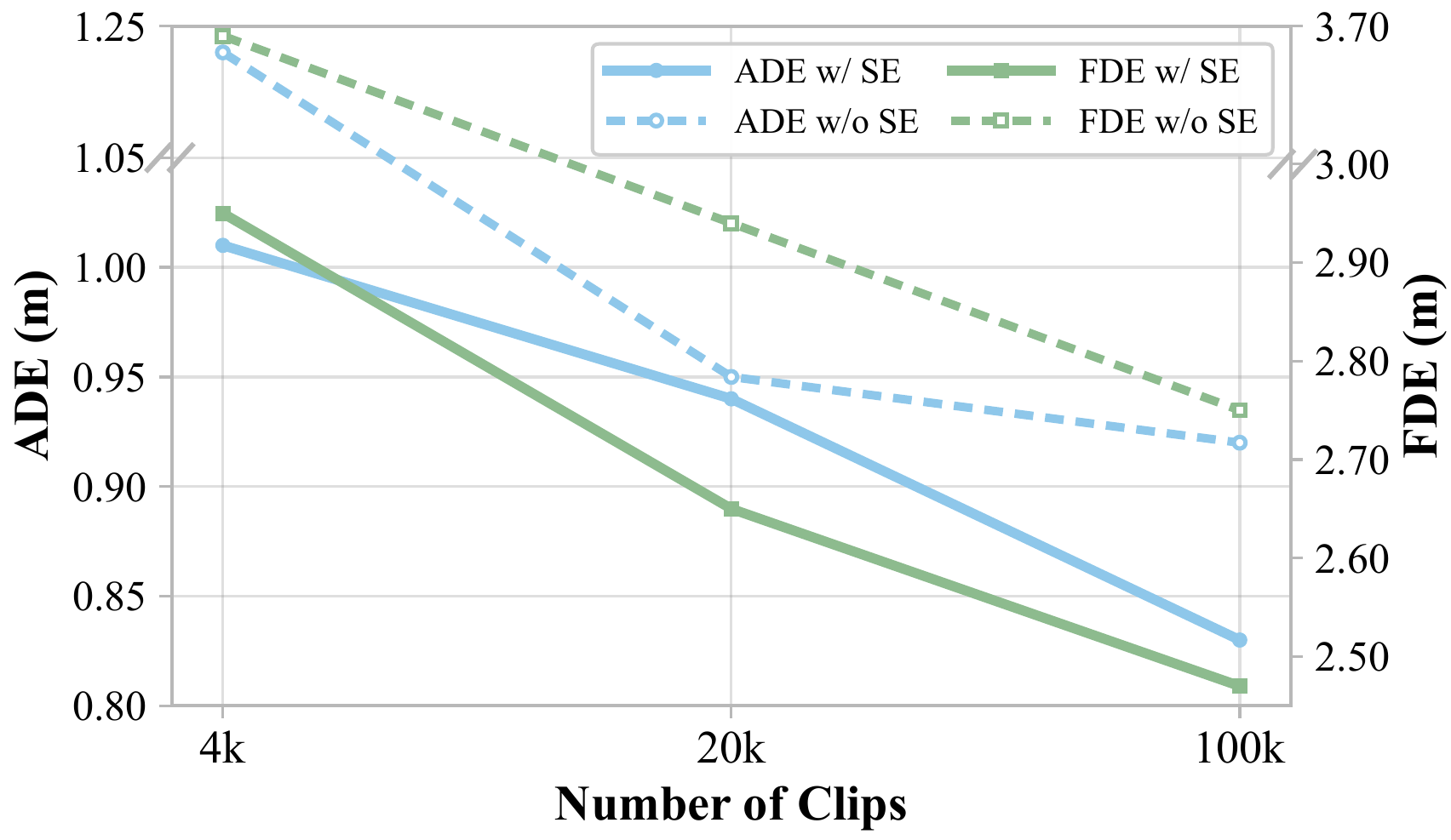
Selective KV memory. Naturally filters static background while retaining moving objects and safety-critical cues (12× memory reduction).